What LineShine's No.1 ranking means for AI

时隔九年,全球超算之巅再度落回中国。但比"第一"更值得玩味的,是登顶的方式——满机柜的算力,没有一张 GPU,从芯片到操作系统全是国产。这套打法,恰恰是它最该被 AI 圈子认真读一遍的地方。
2026 年 6 月 23 日,德国汉堡,ISC 2026 大会发布第 67 期全球超算 TOP500 榜单。坐上头把交椅的,是一台此前从未在榜上现身的中国系统——"灵晟"(LineShine),由国家超级计算深圳中心部署,HPL(High Performance Linpack,超算界衡量持续算力的标准基准)持续双精度性能 2.198 EFlops,约为 2.736 EFlops 理论峰值的八成,把蝉联多期的美国 El Capitan(1.809 EFlops)压在身后。这是继 2017 年"神威·太湖之光"之后,中国超算时隔九年重返世界第一。

据传,这套系统原本是给海光、曙光规划的,后因众所周知的原因,才辗转交到华为手里部署——一纸出口管制,意外催熟了一条纯国产 CPU 的路线。更耐人寻味的是"敢打榜"这三个字:过去几年,中国手握 E 级超算却屡屡缺席 TOP500,普遍的判断是,怕公开登顶、反招来新一轮针对性制裁,索性把家底藏着;如今灵晟高调登榜,底气恰恰在于芯片、互连、操作系统从里到外全是国产,已经没有哪个环节是别人还能"卡"得住的了。从藏着掖着到敢于亮剑,证明了什么,不言而喻。
一、旧秩序:超算的算力,是"堆"加速器堆出来的
过去十年,超算冲顶的路,几乎是同一条:拼命堆加速器。
E 级竞赛,本质是一场加速器竞赛。当今榜上的几台 E 级机器,无一不是以 GPU、加速器为算力主体:El Capitan 靠的是上万颗把 CPU 与 GPU 封进同一基板的 AMD MI300A,Frontier 与 Aurora 各自堆着成万张 AMD、Intel 的 GPU,欧洲的 JUPITER 则压在英伟达的 Grace Hopper 超级芯片上。CPU 在这些系统里不是没有,但它退居二线,真正贡献双精度峰值的,是其中的 GPU 加速部分(El Capitan 甚至把 CPU 与 GPU 合封成 APU,双精度也主要出自 GPU 那半边)。

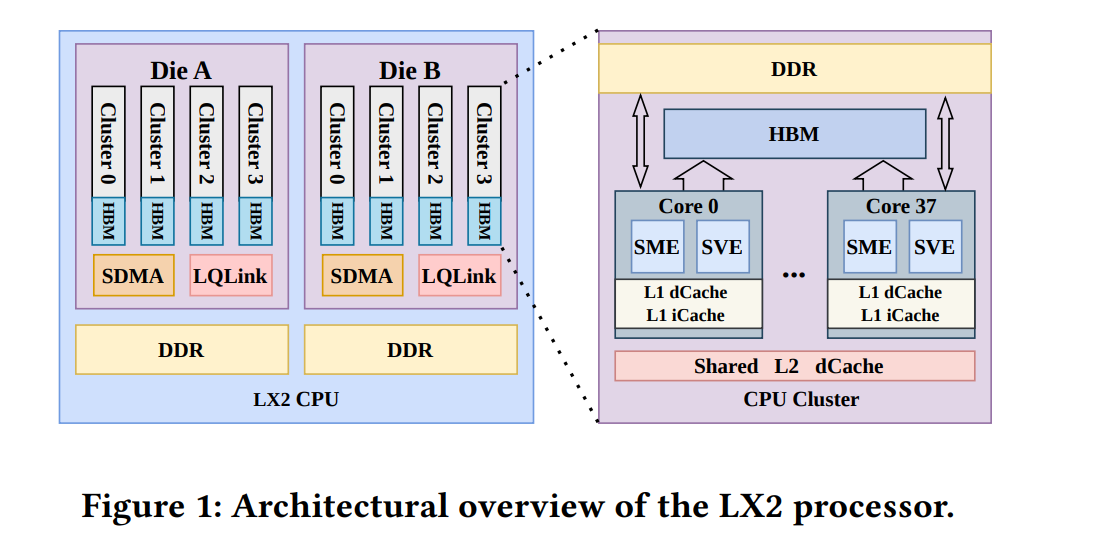
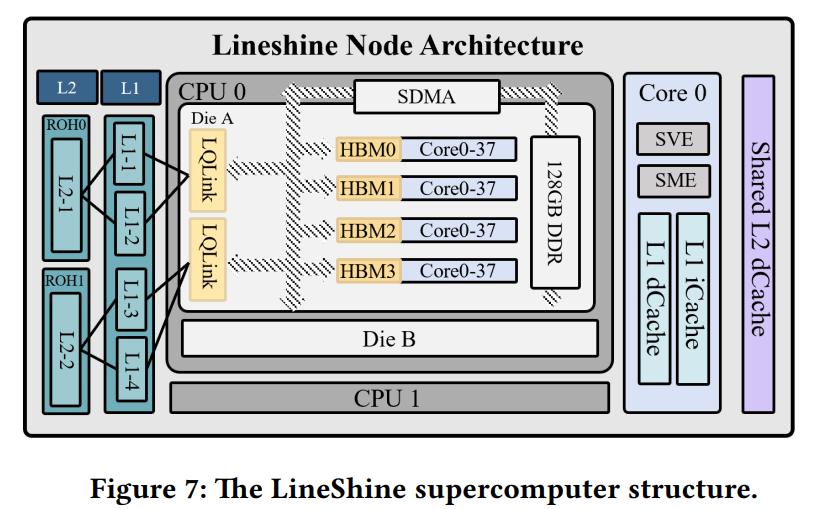
灵晟是这条路上的第一个异类。它的 1379 万个核心,悉数来自约四万七千颗国产 LX2 处理器——论文里它代号 LX2,其原型正是华为鲲鹏 920F,一颗 2019 年便已成型、为浮点而生的 HPC 专用 CPU。整机由 92 个机柜垒成,跑在 1.55 GHz,以自研的"灵启"网络互连,操作系统是麒麟,整机功耗 42.2 MW,能效约 52 GFlops/W。从头到尾,没有一张加速卡。
还有一处值得单说:HBM。CPU 带 HBM 本身不算新鲜——富岳的 A64FX 早在 2020 年就用了片上 HBM2,Intel 的 Xeon Max 也做过。灵晟的分量在"国产"二字:据官方介绍,它集成了首颗国产 HBM,而 HBM 长期被 SK 海力士、三星、美光垄断,更是美国 2024 年底出口管制点名封锁的卡脖子环节。目前国内能量产 HBM 的基本只有华为一家(分 BL、ZQ 两型,形制与传统 HBM 也不太一样)——照此推断,这颗国产 HBM 多半出自华为。于是这台世界第一的超算,从 CPU 到 HBM、网络、操作系统,是一整套国产组合,这正是前面"敢打榜"底气的最后一块拼图。
海外对这条纯 CPU 路线起初并不看好,Tom's Hardware 此前报道时甚至在标题底下撂了一句 "Good luck with that"。如今好运成了实绩。一台没有加速器的超算登上世界第一,第一层意义是它打破了"冲顶必堆加速器"的铁律;而要看懂它对 AI 的第二层意义,得先弄明白:在 AI 时代,加速器——尤其是 GPU——究竟把超算逼到了一个怎样尴尬的位置。
二、AI 时代:GPU 称王,超算反而尴尬
这十年,真正改写算力格局的,是 AI;而 AI 的算力宝座,被 GPU 牢牢坐住。这并非因为 GPU 这套图形时代的老架构天生适合 AI,而是因为 CUDA 用近二十年时间,把库、编译器、运行时和无数调优经验,一层层垒成了一道又高又厚的工程生态壁垒。GPU 称王,本质是 CUDA 称王。
而所谓"超算",早已不是科学计算的专属:今天绝大多数 AI 大模型,本就训练在成千上万张 GPU 组成的大规模并行集群上,这类集群业界同样称作"超算",只不过是为低精度 AI、而非 FP64 而生。真正的分野,在于这台机器是为谁优化。
而算力的大盘,明明白白偏向 AI 那一侧:单是英伟达一年的数据中心营收就约 1937 亿美元,而整个传统 FP64 科学计算市场不过百来亿——大出一个数量级。TOP500 是一张按 FP64 排的榜,更像科学计算的擂台;灵晟登顶它,分量十足,但相对 AI 算力那个大得多的盘子,仍是个相对小众的战场。
而这道"为谁优化"的分野,根子是一条越来越深的裂缝:科学计算与 AI,正在因为精度而分家。
超算的本命是科学计算——算流体、算材料、算气候、算核聚变,这些都吃 FP64 双精度。数值模拟里,误差会沿着迭代一步步放大,精度不够,物理结论就是错的,所以双精度是科学计算不可退让的底线。而 AI、尤其是大语言模型,走的是另一条路:它能容忍很低的数值精度,FP16、FP8 甚至 FP4 都够用,靠的是海量参数的统计涌现,而非逐位的精确。两种负载,对精度的需求南辕北辙。
问题在于,GPU 这条线正在分岔。撑起当今超算双精度的,是 MI250X、MI300A、Grace Hopper 这类 HPC 取向的型号,它们仍保留着强悍的 FP64;可厂商真正的重心和研发预算,正一股脑倒向 AI 取向的产品,而那一侧,双精度在被主动放弃。最直白的例子是英伟达:面向高性能计算的上一代 H100 还有 67 TFLOPS 的 FP64 张量算力,到了主打 AI 的 Blackwell,B200 的双精度被砍到只剩约 37 TFLOPS——省下的晶体管,尽数让给了 FP16、FP8。换句话说,还能满足科学计算的,是 GPU 家族里日渐边缘的那一支。
NPU 那条路就更指望不上了。专为 AI 而生的 NPU(华为昇腾、谷歌 TPU 都属此类)低精度算力凶悍,FP64 却往往孱弱甚至缺席——这也是为什么在死磕双精度的 TOP500 上几乎看不到 NPU:它们在 AI 数据中心称王,却进不了科学计算的牌桌。
于是科学计算被夹在了中间:它既离不开 FP64 的物理仿真,又越来越想借 AI 提速增效——比如用一个训练好的神经网络去替代昂贵的数值求解、或把天气预报的集合规模成倍扩大;可眼下的硬件,AI 的主航道在抛弃双精度,留着双精度的 GPU 日渐边缘,NPU 又干脆不碰高精度。真要把 HPC 与 AI 拧到一处干,往往得搭两套机器、两种精度,中间还横着一条又慢又贵的数据搬运带。算力越堆越多,墙却越垒越厚。
三、CPU 不配做 AI 训练?
以往想用 CPU 做 AI 训练,无异于痴人说梦,原因有三:
其一,CPU 没有矩阵引擎。AI 的核心计算是矩阵乘,GPU 有 Tensor Core、NPU 有矩阵阵列,而传统 CPU 只有标量和向量单元,做矩阵乘是"一个一个乘加"地硬算,吞吐天差地别——顶级 x86 服务器 CPU 的 FP64 峰值不过八九 TFLOPS,连一张老 GPU 都够不上。其二,CPU 没有 CUDA。二十年的库、框架、调优经验,是 GPU 真正的护城河,CPU 这边一片荒芜。其三,在主流的 host-device 模式里,CPU 承担的是调度与数据供给(host),真正的矩阵计算交给 GPU(device)——做 AI 训练时,出算力的本来就不是 CPU。
这条铁律,有一个现成的注脚——日本的富岳。在一片堆满 GPU 的超算榜里,它是少有的纯 CPU 异类:六年前以一身 ARM CPU(A64FX)登顶 TOP500,证明了不靠加速器也能问鼎世界第一。但富岳的 CPU 只有 SVE 向量单元、没有矩阵单元,整颗芯片的 FP64 峰值也才三 TFLOPS 出头;它是一台顶尖的科学计算机器,却始终没能成为一台训 AI 的机器。富岳恰好印证了那条铁律:纯 CPU 能跻身超算之巅,凭的是科学计算的硬实力,与 AI 训练无关。
灵晟要改写的,正是这一章。
四、灵晟改变了什么——这是一场革命吗?
灵晟和富岳最大的不同,只在一处,却是要害的一处:它给 CPU 焊上了矩阵。
LX2 是 ARMv9 架构的众核 CPU,单芯片塞进 304 个核,分作两个 die、八个 cluster。每个核身上挂着两套计算单元:SVE(Scalable Vector Extension,可伸缩向量扩展)管向量,SME(Scalable Matrix Extension,可伸缩矩阵扩展)靠专门的 tile 寄存器和外积(outer-product)指令做矩阵乘。SME 是 ARM 近年新增的矩阵扩展,此前主要出现在消费级芯片上(如 2024 年的 Apple M4);灵晟把它——连同它的 FP64 形态——用到了超算规模。
矩阵一上身,CPU 的双精度算力立刻换了量级。单颗 920F,FP64 算力就有 60.3 TFLOPS。这个数字乍看几乎难以置信——在多数人的常识里,CPU 怎么可能干到 60T 双精度,第一反应往往是怀疑它在拿 INT8、FP8 低精度冒充。但论文白纸黑字写的就是 FP64,ARM 的指令手册也佐证了这条路走得通:SME 的浮点外积指令 FMOPA 确有双精度形态,这 60T,是用 512-bit 的 SME 矩阵单元、实打实做 FP64 外积乘加堆出来的。
把这 60.3 TFLOPS 放进坐标系,才知道它有多扎眼。前面说过,被 AI 带偏的英伟达 B200,双精度只剩 37 TFLOPS——而一颗 CPU 的 FP64,竟越过了 B200,直逼 AMD MI300A 那颗顶级 HPC 芯片的双精度向量水平。再回看那些"正常"的 CPU,顶级 x86 不过八九 TFLOPS、富岳的 A64FX 才三 TFLOPS——920F 是它们的十几乃至二十倍。一颗 CPU,做到了顶级 HPC GPU 量级的双精度算力。
但真正让灵晟脱胎换骨的,不是这个数字,而是这块矩阵单元的"身份"。在 GPU 和 NPU 的世界里,矩阵引擎始终是一块独立的器件,得靠驱动隔着总线投喂;而在 920F 上,矩阵根本不是一块"器件",它就是 CPU 指令集里的几条指令——SME 与标量、向量指令共用同一条流水线、同一组寄存器、同一片缓存。再加上三百多个核之间维持的全片 Cache 一致性,标量负责的控制、向量负责的粘合、矩阵负责的重算,就不再是三颗芯片、三套地址空间,而是同一段程序里的三类指令,活在同一片内存里。即便是英伟达——它也自研了 ARM 架构的 Grace CPU,用 NVLink-C2C 把 Grace 与 GPU 紧紧缝在一起——也仍是 CPU 主控、GPU 主算的两层结构:Grace 负责控制与数据供给,FP64 与张量这些重活仍压在 GPU 上。灵晟则把这道界线整个抹掉了。
这一点,正是它对 AI 最要紧的地方。
已经有团队在灵晟上,把一个 FP64 高精度、物理可解释的数值气候模式,与一套数据驱动的 AI 预报系统,缝进了同一条工作流:数值模式出 174 个物理集合成员,AI 以极低成本扩出 1600 个,两者跑在同一套同构的 CPU 系统上、融成 1774 成员的概率预报,把预报技巧从欧洲中期天气预报中心的 71.8 分提到 75.9 分,整套十年回报算例在全机上 14.6 小时跑完。传统路线里,HPC 与 AI 往往分属两套机器、两种精度,数据要在它们之间反复搬运;在灵晟上,二者跑在同一种硬件、同一条工作流里,省去了这道又慢又贵的跨系统搬运。 上一节那道"科学计算与 AI 分家"的尴尬,就这样被一套同构的 CPU 系统抹平了——这才是官方所谓"超智融合"四个字真正的物理地基。
更要紧的是,这台机器把"CPU 不能训 AI"那条铁律也一并打破了。同样跑在灵晟上、同样没有一张 GPU 的,还有两项实测:一项训出了 115 亿参数的混合专家(MoE)通用机器学习原子间势模型,在约 1240 万核心上单精度跑出 1.2 EFLOPS,把过去要熬上几周的训练压进几个小时;另一项在 CPU 上从头训出了一个 60 亿参数的扩散 Transformer 生成模型,端到端持续 1.54 EFLOPS——前向、反向、优化器一应俱全的完整训练,不是只跑推理。在业界的大模型训练对照中,从 A100、H100 到 B200、MI250X 几乎全是 GPU 集群(这类集群也被称作"大规模并行超算"),而灵晟上的这项,是其中唯一的 CPU。它们至少说明:纯 CPU,真能训十亿级的 AI 大模型。
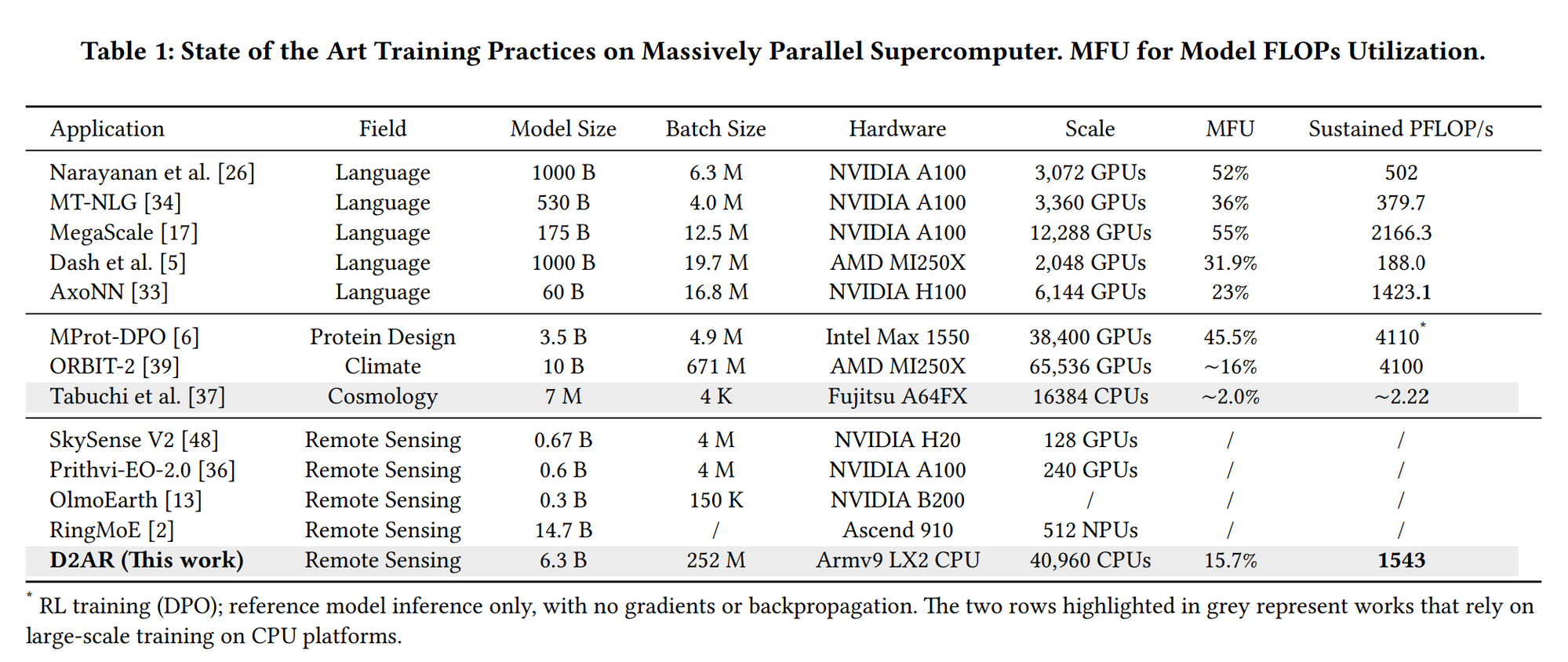
论颠覆 GPU,它还没这个资格:几项实测清一色是科学计算,没有一项去训大模型——科学 AI 必须用 FP32 乃至 FP64 才守得住精度,恰是灵晟的强项,而 LLM 吃的是 FP8、FP4 低精度,灵晟在这类低精度上还没显出专门的加速能力。但论改写规则,它确实一口气捅破了两条公认的铁律:冲顶 E 级不必再堆加速器,CPU 也不再与 AI 训练绝缘——更把 HPC 与 AI 拧成了一台机器,为"超智融合"走出了一条别人没走通的路。
五、训练、推理,还是只擅科学计算?
纯 CPU 能训出十亿级模型,是真的;但要说它训得更省、更快,那就错了。前面那两项训练的 MFU(模型算力利用率)只有约 24% 和 15.7%,都低于同类 GPU 的 23%–55%;而为了用满 SME,团队连 cuBLAS 都没得用,只能手写矩阵乘内核、自拼一套异步运行时来模拟 CUDA——GPU 二十年的软件便利,在这边要一行行重写回来。更直接的是:连华为自己训大模型,用的也是昇腾 NPU,而不是鲲鹏 CPU。纯 CPU 训 LLM,既不是产业趋势,也没有能效优势。
那它真正的长处在哪?不在裸算力,而在那些控制密集、数据密集的环节——复杂预处理、分布式 I/O 编排、内存管理、通信调度,以及与大型存储系统的耦合。这正是以 CPU 为中心的超算被论证出的天然优势:把计算、控制、数据拢在一处协同,而不是单点堆吞吐。
这对应的最佳场景,是科学智能(AI for Science,AI4S)与 HPC-AI 融合:一个任务既要 FP64 仿真、又要 AI,让两者跑在同一套同构的 CPU 系统、同一条工作流里,省掉在两套机器之间反复搬运的麻烦——前面那套汛期预报已经验证。
至于大模型,无论训练还是推理,今天都跑在专门的 GPU 或 NPU 上——英伟达如此,华为也一样(昇腾既用于训练,也用于推理)。把这套以 FP64 见长、在低精度上却乏善可陈的 CPU 架构,说成更适合大模型推理,目前并无依据:HPL-MxP 上它的低精度只比双精度快 3.6 倍,而装了专用低精度单元的机器普遍能放大到 9 倍以上——至少说明灵晟缺少同等的专用低精度加速。
能效也得分着看:FP64 这一侧,一颗 700W 的 CPU 给出 GPU 级的双精度,对气候、材料、药物这类高精度科学计算是真省;低精度 AI 这一侧,它还没有专用单元,暂时谈不上优势。
但"把算力收进 CPU"这件事,背后是有硬道理的,而且恰恰关乎能效。现代芯片里最费电的,从来不是计算本身,而是数据搬运:Horowitz 在 ISSCC 2014 给出的经典数据显示,一次浮点运算只耗 0.4–3.7 皮焦,一次片外内存访问却要 1300–2600 皮焦——近千倍之差。让数据少跑路,远比让算力更猛更省电。而经典的 host-device 结构把数据钉在来回搬运的路上:CPU 一片地址空间、GPU 另一片,中间隔着 PCIe。这些年的紧耦合设计已经在收窄这道缝——英伟达 Grace-Hopper 用 NVLink-C2C 做一致内存,AMD MI300A 干脆把 CPU 与 GPU 合封;而灵晟更进一步,把标量、向量、矩阵连同 HBM 收进同一颗 cache 一致的芯片,从根上砍掉这段搬运。这也是 x86 的 ACE 指令集、ARM 的 SME 齐往这个方向走的共同动机。灵晟则把集成推得最彻底——连 host-device 都不要,整台机器就是一颗自洽的 CPU。但这未必是大模型的最优解,更像科学计算 AI 的一个局部解;它真正诱人的地方,是指向了另一种可能的全局最优——一旦打破 host 与 device 的隔阂,计算过程便有机会自我调度、自我优化,而调度与动态控制,恰是 CPU 的看家本领。
至于软件生态,它从来是跟着价值走的。CUDA 不是先有生态才有 GPU,而是 GPU 先证明了价值、生态花二十年才长起来。所以"等 FP8、等生态"其实把因果说反了:只要这条路在能效上确实更优,软硬件自会跟上;真正的悬念,是这份理论上的能效红利,能不能在低精度 AI 上兑现,又能不能赢过同样在做集成的 GPU 阵营。
这并不意味着 CPU 要从英伟达手里夺回数据中心——那场仗早已分晓,GPU 与 CUDA 赢得干干净净。给 CPU 加上矩阵单元的这股潮流(x86 的 ACE、ARM 的 SME),更多是让 CPU 自己也能承接一部分 AI 负载;况且推动它的 Intel 与 AMD 自家都有 GPU,无人真正把筹码全押在纯 CPU 上。把 GPU 彻底移出系统、一路走到纯 CPU 的,目前唯灵晟一家;而它选定的战场,也不在英伟达锁死的 AI 数据中心,而在超算与科学计算。
说到底,AI 算力眼下最硬的瓶颈,已经从"算得快不快"转移到了内存墙与功耗墙——数据在芯片之间、在成千上万张卡之间反复搬运的代价,正是英伟达式 GPU 集群一路堆规模时迟早要撞上的天花板。灵晟把矩阵做进 CPU 指令集、用全片 cache 一致性把算力、控制与内存收进同一片地址空间,瞄准的正是这堵墙。它这一版在低精度上还没显出起色、进不了大模型的实战,但趟出的这套"统一内存、统一指令"的架构思路,很可能是日后突破集群规模与功耗墙时,最值得参照的一块试金石。这一步能走多远,下一代 LX2 自会给出答案。
参考
- TOP500. LineShine Debuts at No. 1 as the TOP500 Enters a New Global Exascale Era. https://top500.org/news/lineshine-debuts-no-1-top500-enters-new-global-exascale-era/
- Tom's Hardware. China's LineShine supercomputer dethrones US El Capitan, secures first place in Top 500 list. https://www.tomshardware.com/tech-industry/supercomputers/chinas-lineshine-supercomputer-dethrones-us-el-capitan-secures-first-place-in-top-500-list
- SCMP. Return to the top: China's LineShine beats US El Capitan in TOP500 supercomputer rankings. https://www.scmp.com/news/china/science/article/3358107/return-top-chinas-lineshine-beats-us-el-capitan-top500-supercomputer-rankings
- 国家超级计算深圳中心 / Sun Yat-sen University. 灵晟超级计算机与卢宇彤. https://www.szgm.gov.cn/english/topic/KeyFacilitiesinGM/content/post_11260363.html
- Arm Developer. Arm Scalable Matrix Extension (SME) Introduction. https://developer.arm.com/community/arm-community-blogs/b/architectures-and-processors-blog/posts/arm-scalable-matrix-extension-introduction
- Zhou, Wang, et al. Breaking the Training Barrier of Billion-Parameter Universal Machine Learning Interatomic Potentials. arXiv:2604.15821. https://arxiv.org/abs/2604.15821
- Zhang, Dong, et al. Transforming the Use of Earth Observation Data: Exascale Training of a Generative Compression Model with Historical Priors for up to 10,000x Data Reduction. arXiv:2605.08633. https://arxiv.org/pdf/2605.08633
- Chen, Xu, et al. Exascale Hybrid Numerical-AI Ensembles for Operational Flood-Season Forecasting in East Asia. arXiv:2605.24896. https://arxiv.org/abs/2605.24896
- heise online. AMD and Intel specify AI instruction set "ACE" for x86 processor cores. https://www.heise.de/en/news/AMD-and-Intel-specify-AI-instruction-set-ACE-for-x86-processor-cores-11339014.html
- AMD. Instinct MI300A Data Sheet(FP64 规格,对比基准). https://www.amd.com/content/dam/amd/en/documents/instinct-tech-docs/data-sheets/amd-instinct-mi300a-data-sheet.pdf
- NVIDIA. H100 / HGX B200 Datasheet(FP64 规格,对比基准). https://resources.nvidia.com/en-us-gpu-resources/h100-datasheet-24306